kubernetes 网络
1.开篇
Docker容器诞生以来,,如何确定合适的网络方案是亟待解决的难题之一.在日趋复杂的业务场景下,网络的复杂性也呈几何级数上升.本篇首先回顾了Docker容器的网络通信,然后介绍Kubernertes的网络模型.在Kubernetes集群中,IP地址的分配对象是以Pod为单位,而非容器.同一个Pod内的所有容器共享同一个网络名称空间
2 容器网络基础
一个Linux容器的网络栈是被隔离在它自己的Network Namespace中,Network Namespace包括了:网卡(Network Interface),回环设备(Lookback Device),路由表(Routing Table)和iptables规则,对于服务进程来讲这些就构建了它发起请求和相应的基本环境。而要实现一个容器网络,离不开以下Linux网络功能:
- 网络命名空间:将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信
- Veth Pair:Veth设备对的引入是为了实现在不同网络命名空间的通信,总是以两张虚拟网卡(veth peer)的形式成对出现的。并且,从其中一端发出的数据,总是能在另外一端收到
- Iptables/Netfilter:Netfilter负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核中;Iptables模式是在用户模式下运行的进程,负责协助维护内核中Netfilter的各种规则表;通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制
- 网桥:网桥是一个二层网络虚拟设备,类似交换机,主要功能是通过学习而来的Mac地址将数据帧转发到网桥的不同端口上
- 路由: Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里
2.Docker容器网络模型
2.1 同节点容器通信
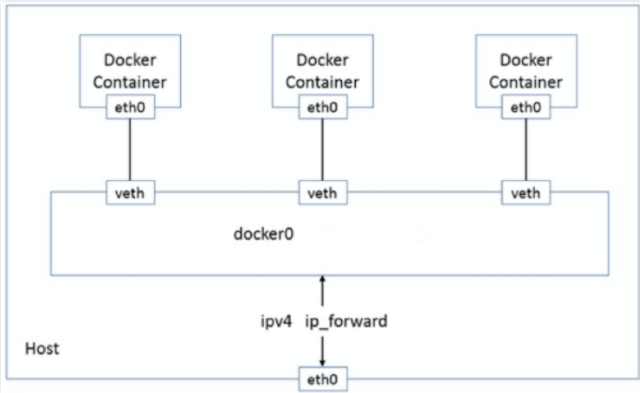
Docker容器网络的原始模型主要用到的就是Bridge桥接网络.Docker守护进程首次启动时,会在当前宿主机节点创建一个名为docker0 的虚拟网桥设备.并默认配置其使用172.17.0.0/16的网络.
Host和Container网络模型使用场景非常少.不再费篇幅介绍
并且为该主机节点上的每一个容器分配一个虚拟的以vethxxx 开头的虚拟网卡.从而使得同一节点下的所有容器都可以在二层网络模式下.利用docker0 虚拟网桥实现容器和容器之间,容器和宿主机节点之间的网络通信.
同一宿主机节点下的容器网络通信方式如下
2.2 不同节点容器通信
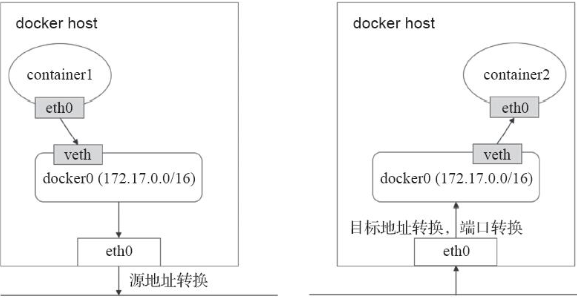
以上是同节点上的容器通信方式.对于不同节点的容器之间进行通信,Docker则无能为力.因为每个节点的docker0网桥分配的虚拟IP都是同一网段,所以不同宿主机节点上的容器可能使用的是同一个IP地址,双方并不清楚对方容器具体在哪台节点.
解决此问题的方式是NAT.所有容器均会被NAT隐藏在节点网络之内.他们发往Docker主机外部的所有流量都会SNAT后出去,容器若要接入Docker主机外部的流量,则需要事先将网络端口暴露到宿主机的端口..然后对方容器的流量达到宿主机后再执行DNAT转发给目的容器.
不同宿主机节点下的容器网络通信方式如下
这种解决方式在网络规模庞大的时候兼职就是个灾难.转发效率非常低下,宿主机上端口变成一种稀缺资源.
3. Kubernetes网络模型
Kubernetes的网络模型主要用于解决四类通信需求:
(1) 容器间通信
Pod对象内的各容器共享同一个网络名称空间.所有运行于同一个Pod内部的容器与同一主机上的多个进程类似.彼此之间可以通过localhost 或者lo 回环接口进行通信.
例如下图3-1所示,每个节点上的Container1和container2容器在一个Pod内部,共享同一个IP地址和网络接口
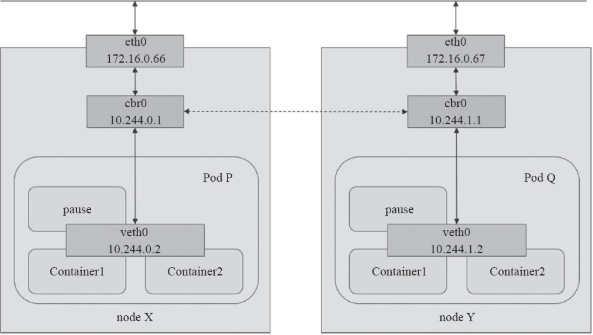
图 3-1 Pod网络
(2) Pod间通信
Kubernertes要求每个Pod对象需要运行于同一个平面网络中,并且都拥有一个集群内全局唯一的IP地址,可以直接于其他Pod通信.例如上图3-1中的Pod P和Pod Q之间通信.另外,运行Pod的各节点也会通过桥接设备等持有此平面网络中的一个IP地址,如图3-1中的cbr0接口,这就意味着Node到Pod间的通信也可在此网络上直接进行。因此,Pod间的通信或Pod到Node间的通信比较类似于同一IP网络中主机间进行的通信。
(3) Service与Pod间通信
Service资源的专用网络也称为集群网络(Cluster Network),需要在启动kube-apiserver时经由“–service-cluster-ip-range”选项进行指定,如10.96.0.0/12,而每个Service对象在此网络中均拥一个称为Cluster-IP的固定地址。管理员或用户对Service对象的创建或更改操作由API Server存储完成后触发各节点上的kube-proxy,并根据代理模式的不同将其定义为相应节点上的iptables规则或ipvs规则,借此完成从Service的Cluster-IP与Pod-IP之间的报文转发,如图3-2所示。
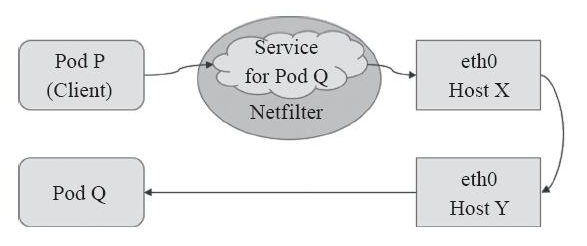
图 3-2 Service和Pod
(4) 集群外部到Pod对象之间的通信
将集群外部的流量引入到Pod对象的方式有受限于Pod所在的工作节点范围的节点端口(nodePort)和主机网络(hostNetwork)两种,以及工作于集群级别的NodePort或LoadBalancer类型的Service对象。不过,即便是四层代理的模式也要经由两级转发才能到达目标Pod资源:请求流量首先到达外部负载均衡器,由其调度至某个工作节点之上,而后再由工作节点的netfilter(kube-proxy)组件上的规则(iptables或ipvs)调度至某个目标Pod对象。
4. Kubernetes CNI插件
Kubernetes设计了以上四种网络模型.但是Kubernetes自己并不负责网络具体工作,而是交给的了第三方网络插件.为了规范以及兼容各种解决方案.CoreOS和Google联合制定了CNI(Container Network Interface)标准,旨在定义容器网络模型规范。它连接了两个组件:容器管理系统和网络插件。它们之间通过JSON格式的文件进行通信,以实现容器的网络功能.具体的网络工作均由插件来实现,包括创建容器netns、关联网络接口到对应的netns以及为网络接口分配IP等。
CNI的基本思想是:容器运行时环境在创建容器时,先创建好网络名称空间(netns),然后调用CNI插件为这个netns配置网络,而后再启动容器内的进程。
Kubernetes要求网络插件需要满足以下基本原则:
- Pod无论运行在任何节点都可以互相直接通信,而不需要借助NAT地址转换实现。
- Node与Pod可以互相通信,在不限制的前提下,Pod可以访问任意网络。
- Pod拥有独立的网络栈,Pod看到自己的地址和外部看见的地址应该是一样的,并且同个Pod内所有的容器共享同个网络栈。
CNI本身只是规范,付诸生产还需要有特定的实现。目前,CNI提供的插件分为三类:main、meta和ipam。main一类的插件主要在于实现某种特定的网络功能,例如loopback、bridge、macvlan和ipvlan等;meta一类的插件自身并不提供任何网络实现,而是用于调用其他插件,例如调用flannel;ipam仅用于分配IP地址,而不提供网络实现。
CNI具有很强的扩展性和灵活性,例如,如果用户对某个插件具有额外的需求,则可以通过输入中的args和环境变量CNI_ARGS进行传递,然后在插件中实现自定义的功能,这大大增加了它的扩展性。另外,CNI插件将main和ipam分开,赋予了用户自由组合它们的机制,甚至一个CNI插件也可以直接调用另外一个CNI插件。CNI目前已经是Kubernetes当前推荐的网络方案。常见的CNI网络插件包含如下这些主流的项目.
Flannel.
一个为Kubernetes提供叠加网络的网络插件,它基于Linux TUN/TAP,使用UDP封装IP报文来创建叠加网络,并借助etcd维护网络的分配情况。
Calico
一个基于BGP的三层网络插件,并且也支持网络策略来实现网络的访问控制;它在每台机器上运行一个vRouter,利用Linux内核来转发网络数据包,并借助iptables实现防火墙等功能。
Weave Net:
Weave Net是一个多主机容器的网络方案,支持去中心化的控制平面,在各个host上的wRouter间建立Full Mesh的TCP连接,并通过Gossip来同步控制信息。
5. Kubernetes CNI网络通信
实际上CNI的容器网络通信流程跟前面的基础网络一样,只是CNI维护了一个单独的网桥来代替 docker0。这个网桥的名字就叫作:CNI 网桥,它在宿主机上的设备名称默认是:cni0。cni的设计思想,就是:Kubernetes在启动Infra容器之后,就可以直接调用CNI网络插件,为这个Infra容器的Network Namespace,配置符合预期的网络栈。
CNI插件三种网络实现模式:

- overlay 模式是基于隧道技术实现的,整个容器网络和主机网络独立,容器之间跨主机通信时将整个容器网络封装到底层网络中,然后到达目标机器后再解封装传递到目标容器。不依赖与底层网络的实现。实现的插件有flannel(UDP、vxlan)、calico(IPIP)等等
- 三层路由模式中容器和主机也属于不通的网段,他们容器互通主要是基于路由表打通,无需在主机之间建立隧道封包。但是限制条件必须依赖大二层同个局域网内。实现的插件有flannel(host-gw)、calico(BGP)等等
- underlay网络是底层网络,负责互联互通。 容器网络和主机网络依然分属不同的网段,但是彼此处于同一层网络,处于相同的地位。整个网络三层互通,没有大二层的限制,但是需要强依赖底层网络的实现支持.实现的插件有calico(BGP)等等
参考资料
kubernetes容器网络: https://tech.ipalfish.com/blog/2020/03/06/kubernetes_container_network/ (伴鱼团队)
<kubernetes进阶实战> 11.1 马永亮

